Przykładowa procedura projektowania obejmuje sekwencyjne rozwiązanie następujących trzech zadań:
Definicja przedmiotu badań;
Określenie struktury próbki;
Określanie wielkości próby.
Zazwyczaj, obiekt badań marketingowych to zbiór obiektów obserwacji, którymi mogą być konsumenci, pracownicy firmy, pośrednicy itp. Jeśli ten zestaw jest tak mały, że Grupa poszukiwawcza ma niezbędne możliwości pracy, finansów i czasu, aby nawiązać kontakt z każdym z jego elementów, wówczas całkiem realistyczne jest prowadzenie ciągłego badania całej populacji. W takim przypadku, po ustaleniu przedmiotu badań, można przejść do kolejnej procedury (wyboru sposobu zbierania danych, narzędzia badawczego i sposobu komunikacji z odbiorcami).
Jednak w praktyce bardzo często nie jest możliwe lub właściwe prowadzenie ciągłych badań całej populacji. Mogą być tego następujące przyczyny:
Niemożność nawiązania kontaktu z niektórymi elementami populacji;
Nieracjonalnie wysokie koszty przeprowadzenia pełnego badania lub istnienie ograniczeń finansowych, które nie pozwalają na przeprowadzenie pełnego badania;
Krótki czas przeznaczony na badanie, wynikający z utraty przydatności informacji w czasie lub z innych powodów, który nie pozwala na zebranie, usystematyzowanie i analizę obszernych danych dla całej populacji.
Dlatego duże i rozproszone populacje są często badane za pomocą próby, która, jak wiadomo, jest rozumiana jako część populacji, mająca na celu reprezentowanie populacji jako całości.
Dokładność, z jaką próbka odzwierciedla populację jako całość, zależy od strukturę i wielkość próbki.
Istnieją dwa podejścia do struktury próbki- probabilistyczny i deterministyczny.
Probabilistyczne podejście do struktury próbki zakłada, że dowolny element populacji można wybrać z pewnym (nie zerowym) prawdopodobieństwem. Istnieć Różne rodzaje próbki oparte na teorii prawdopodobieństwa (typowe, zagnieżdżone itp.). Najprostszą i najczęstszą w praktyce jest prosta próba losowa, w której każdy element populacji ma równe prawdopodobieństwo wybrania do badań.
Próbkowanie probabilistyczne jest dokładniejsze, pozwala badaczowi ocenić stopień wiarygodności zebranych przez siebie danych, choć jest bardziej skomplikowane i droższe od próbkowania deterministycznego.
Podejście deterministyczne do przykładowej struktury zakłada, że selekcji elementów populacji dokonuje się metodami opartymi albo na względach wygody, albo na decyzji badacza, albo na grupach przypadkowych.
ze względów wygody, polega na wyborze dowolnych elementów populacji w oparciu o łatwość nawiązania z nimi kontaktu. Niedoskonałość tej metody wynika być może z małej reprezentatywności uzyskanej próbki, gdyż Dogodne dla badacza elementy populacji mogą nie być wystarczająco charakterystycznymi przedstawicielami populacji ze względu na ich nielosowy i nieuzasadniony dobór.
Z drugiej jednak strony prostota, ekonomiczność i efektywność badań prowadzonych tą metodą zapewniły jej dość szerokie rozpowszechnienie w praktyce, a przede wszystkim w prowadzeniu badań wstępnych mających na celu wyjaśnienie głównych problemów.
Metoda próbkowania oparta na metodzie na podstawie decyzji badacza, polega na wyborze elementów populacji, które w jego mniemaniu są jej charakterystycznymi przedstawicielami. Metoda ta jest doskonalsza od poprzedniej, gdyż opiera się na orientacji na charakterystycznych przedstawicieli badanej populacji, chociaż są oni wybierani na podstawie subiektywnych wyobrażeń badaczy na jej temat.
Metoda pobierania próbek oparta na normy warunkowe, polega na doborze charakterystycznych elementów populacji zgodnie z wcześniej uzyskanymi cechami populacji jako całości. Charakterystyki te można uzyskać przeprowadzając badania wstępne i w odróżnieniu od poprzedniej metody nie mają one charakteru subiektywnego. Dlatego Ta metoda jest bardziej zaawansowana, pozwala na uzyskanie populacji prób nie mniej reprezentatywnych niż próby probabilistyczne przy znacznie niższych kosztach przeprowadzenia badania.
Po wybraniu struktury próbki (podejścia do jej powstawania, rodzaju probabilistycznego lub rzucającego tworzenia się próbki deterministycznej) badacz będzie musiał wyznaczyć objętość, tj. liczba elementów próbki.
Wielkość próbki decyduje o wiarygodności informacji uzyskane w wyniku badania, a także koszty niezbędne do badania. Wielkość próbki zależy na poziomie jednorodności lub różnorodności badanych obiektów.
Im większa liczebność próby, tym większa jej dokładność i większy koszt przeprowadzenia badania. Przy probabilistycznym podejściu do struktury próbki, jej objętość można wyznaczyć za pomocą znanych wzorów statystycznych, w oparciu o określone wymagania dotyczące jej dokładności.
W praktyce stosuje się kilka podejść do określenia wielkości próby:
1. Podejście arbitralne w oparciu o zastosowanie „praktycznej zasady”. Na przykład zakłada się bez dowodów, że aby uzyskać dokładne wyniki, próbka musi stanowić 5% populacji. Podejście to jest proste i łatwe do wdrożenia, jednak nie jest możliwe ustalenie dokładności uzyskanych wyników. Przy wystarczająco dużej populacji może to być również dość drogie.
Wielkość próbki można ustalić w oparciu o pewne wcześniej ustalone warunki. Na przykład klient badania rynku wie, że badając opinię publiczną, próba wynosi zwykle 1000-1200 osób, dlatego zaleca, aby badacz trzymał się tej liczby. W przypadku prowadzenia corocznych badań na konkretnym rynku, co roku wykorzystuje się próbę o tej samej liczebności. W przeciwieństwie do pierwszego podejścia, tutaj przy ustalaniu liczebności próby posługuje się znaną logiką, która jednak jest bardzo podatna na zagrożenia.
Przykładowo przy przeprowadzaniu niektórych badań dokładność może być mniejsza niż w badaniu opinii publicznej, a liczebność populacji może być wielokrotnie mniejsza niż w badaniu opinii publicznej. Dlatego takie podejście nie uwzględnia bieżących okoliczności i może być dość kosztowne.
W niektórych przypadkach koszt przeprowadzenia badania jest głównym argumentem przy ustalaniu wielkości próby. Tym samym budżet na badania marketingowe przewiduje koszt przeprowadzenia niektórych badań, którego nie można przekroczyć. Oczywiście wartość otrzymanych informacji nie jest brana pod uwagę. Jednak w niektórych przypadkach nawet mała próbka może dać dość dokładne wyniki.
Zasadne wydaje się rozpatrywanie kosztów nie w sposób bezwzględny, ale w odniesieniu do przydatności informacji uzyskanych w wyniku badań. Klient i badacz powinni wziąć pod uwagę różne wielkości próbek i metody gromadzenia danych, koszty i inne czynniki
2. Liczebność próby od poziomu przedziału ufności błędu dopuszczalnego, o czym, jak już wspomniano, decyduje odpowiednia trafność ostatecznych uogólnień: od wysokich do przybliżonych. Mamy tu jednak na myśli tzw. błędy losowe, związane z naturą wszelkich błędów statystycznych. To właśnie one obliczane są jako błędy reprezentatywności prób probabilistycznych.
V. I. Paniotto podaje następujące obliczenia dla reprezentatywnej próby przy założeniu 5-procentowego błędu (tabela 4.2).
Tabela 4.2
Szacunkowa przykładowa tabela
Dla populacji liczącej ponad 100 000 osób próba wynosi 400 jednostek. Jeśli jednak mamy na myśli populacje ogólne liczące 5 tysięcy i więcej, to zgodnie z obliczeniami tego samego autora można wskazać wielkość rzeczywistego błędu próbkowania w zależności od jego wielkości, co jest dla nas bardzo ważne , mając na uwadze, że wielkość błędu dopuszczalnego zależy od celu badań i niekoniecznie musi sięgać poziomu 5 proc.
Tabela 4.3
Tabela obliczeń
|
Wielkość próby, jeśli populacja 5000 | ||||||||
|
Rzeczywisty błąd dla danej liczebności próby, % |
Oprócz błędów przypadkowych możliwe są błędy systematyczne. Zależą one od organizacji badania reprezentacyjnego. Są to różne odchylenia próbki w kierunku jednego z biegunów parametru próbki.
3. Wielkość próby na podstawie analizy statystycznej . Podejście to opiera się na określeniu minimalnej wielkości próby w oparciu o określone wymagania dotyczące rzetelności i rzetelności wyników. Wykorzystuje się go także do analizy wyników uzyskanych dla poszczególnych podgrup tworzących się w ramach próby ze względu na płeć, wiek, poziom wykształcenia itp. Wymagania dotyczące rzetelności i dokładności wyników dla poszczególnych podgrup narzucają pewne wymagania dotyczące wielkości próby jako całości.
Najbardziej teoretycznie uzasadnione i prawidłowe podejście do wyznaczania liczebności próby opiera się na wyliczaniu przedziałów miarodajnych. Pojęcie zmienności charakteryzuje stopień odmienności (podobieństwa) odpowiedzi respondentów na dane pytanie. W ściślejszym sensie zmienność wartości cechy w agregacie to różnica jej wartości pomiędzy różnymi jednostkami danego agregatu w tym samym okresie lub punkcie czasu. Wyniki odpowiedzi na pytania ankietowe przedstawiane są zazwyczaj w postaci krzywej rozkładu (ryc. 4.1). Przy dużym podobieństwie odpowiedzi mówią o małej wariancji (wąska krzywa rozkładu), a przy małym podobieństwie odpowiedzi o dużej zmienności (szeroka krzywa rozkładu).
Jako miarę zmienności przyjmuje się zwykle odchylenie standardowe, które charakteryzuje średnią odległość od średniego wyniku odpowiedzi każdego respondenta na dane pytanie.
Mała odmiana
duże zróżnicowanie
Ryż. 4.1. Krzywe zmienności i rozkładu
Ponieważ wszystkie decyzje marketingowe podejmowane są w warunkach niepewności, zaleca się uwzględnienie tej okoliczności przy ustalaniu wielkości próby. Ponieważ definicja badanych wielkości dla populacji w wąskim zakresie odbywa się na podstawie przykładowe statystyki, wówczas należy ustalić przedział (przedział ufności), w jakim spodziewane są szacunki dla całej populacji oraz błąd ich wyznaczania.
Przedział ufności to przedział, którego skrajne punkty odpowiadają określonemu procentowi pewnych odpowiedzi na pytanie. Przedział ufności jest ściśle powiązany z odchyleniem standardowym badanej cechy w populacji ogólnej: im jest większy, tym szerszy powinien być przedział ufności, aby uwzględnić określony procent odpowiedzi.
Przedział ufności wynoszący 95% lub 99% jest standardem w badaniach marketingowych. Żadna firma nie prowadzi badań rynku z wieloma próbami. A statystyka matematyczna pozwala uzyskać pewne informacje o rozkładzie próbki, mając jedynie dane o zmienności pojedynczej próbki.
Wskaźnikiem tego, w jakim stopniu szacunki prawdziwe dla całej populacji różnią się od szacunków oczekiwanych dla typowej próby, jest błąd standardowy. Co więcej, im większa wielkość próby, tym mniej błędów. Wysoka wartość zmienności powoduje dużą wartość błędu i odwrotnie.
Kiedy jest włączony zadane pytanie istnieją tylko dwie możliwości odpowiedzi, wyrażone procentowo (stosuje się miarę procentową), liczebność próby określa się za pomocą następującego wzoru:

gdzie n jest wielkością próby; z jest znormalizowanym odchyleniem określonym na podstawie wybranego poziomu ufności; p jest znalezioną odmianą próbki; g - (100-r); e jest błędem akceptowalnym.
Przy określaniu wskaźnika zmienności dla określonej populacji wskazane jest przede wszystkim przeprowadzenie wstępnej analizy jakościowej badanej populacji, przede wszystkim w celu ustalenia podobieństwa jednostek populacji pod względem demograficznym, społecznym i innym zainteresowanie badacza. Istnieje możliwość przeprowadzenia badania pilotażowego, wykorzystując wyniki podobnych badań przeprowadzonych w przeszłości. Stosując procentową miarę zmienności, uwzględnia się okoliczność, że maksymalną zmienność osiąga się dla p = 50%, co jest najgorszym przypadkiem. Ponadto wskaźnik ten nie wpływa radykalnie na wielkość próby. Pod uwagę brana jest także opinia klienta badania na temat wielkości próby.
Możliwe jest określenie wielkości próby na podstawie średnich, a nie wartości procentowych.

gdzie s jest odchyleniem standardowym.
W praktyce, jeśli próba była formowana od nowa i nie prowadzono podobnych badań, to s nie jest znane. W takim przypadku wskazane jest określenie błędu e w ułamkach odchylenia standardowego. Wzór obliczeniowy jest konwertowany i przyjmuje następującą postać:
 Gdzie
Gdzie 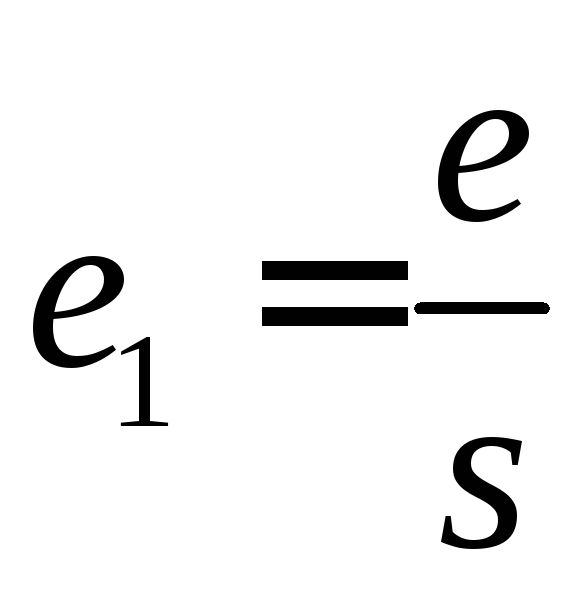 .
.
Powyżej mówiliśmy o agregatach o bardzo dużych rozmiarach. Jednak w niektórych przypadkach populacje nie są duże. Zwykle, jeśli próba stanowi mniej niż pięć procent populacji, wówczas populację uważa się za dużą i obliczenia przeprowadza się według powyższych zasad. Jeżeli liczebność próby przekracza 5% populacji, wówczas tę ostatnią uznaje się za małą i do powyższych wzorów wprowadza się współczynnik korygujący.
Wielkość próbki w tym przypadku określa się w następujący sposób:
 ,
,
gdzie n jest wielkością próby dla małej populacji; n 0 to liczebność próby obliczona według powyższych wzorów; N to wielkość populacji ogólnej.
Oczywiście użycie mniejszych próbek pozwoli zaoszczędzić czas i pieniądze.
Powyższe wzory na obliczenie liczebności próby opierają się na założeniu, że zastosowano się do wszystkich zasad doboru próby, a jedynym błędem próby jest błąd liczebności próby. Należy jednak pamiętać, że wielkość próby decyduje o dokładności wyników, a nie o ich reprezentatywności.
To ostatnie określa się metodą pobierania próbek. Wszystkie wzory na obliczenie liczebności próby zakładają, że reprezentatywność jest gwarantowana poprzez zastosowanie prawidłowych probabilistycznych procedur doboru próby.
O wielkości próby decydują cele analityczne badania, a o jej reprezentatywności – założenia programu. Jest to program, który określa obraz populacji ogólnej niezbędnej do pobierania próbek. Niezależnie od tego, czy będzie to cała populacja, czy jej szczególne formacje strukturalne, wszystkie elementy badanego obiektu, czy tylko przydzielone według kryteriów określonych w programie, na populację ogólną składają się wszystkie jednostki określone w programie obiektu.
Przy deterministycznym podejściu do struktury próbki, w ogólnym przypadku, nie jest możliwe dokładne określenie jej objętości poprzez obliczenia według danego kryterium wiarygodności otrzymanej informacji. W takim przypadku wielkość próby można określić empirycznie. Doświadczenie w prowadzeniu badań marketingowych za granicą może służyć tutaj jako wskazówka. Tak więc podczas badania nabywców zapewniona jest wysoka dokładność próby, nawet jeśli jej wielkość nie przekracza 1% ogółu populacji, podczas przeprowadzania badań nabywców średnich i dużych firm detalicznych, z reguły liczba respondentów (wielkość próby) waha się od 500 do 1000 osób.
Znaczenie procedury wyboru metody gromadzenia informacji pierwotnych i narzędzi badawczych polega na tym, że wyniki tego wyboru decydują zarówno o wiarygodności i dokładności zbieranych informacji, jak i o czasie trwania i wysokich kosztach ich gromadzenia.
Próbka
Próbka Lub ramka próbkowania- zbiór przypadków (obiektów, obiektów, zdarzeń, próbek), przy zastosowaniu określonej procedury, wybranych z populacji ogólnej do udziału w badaniu.
Przykładowe cechy:
- Charakterystyka jakościowa próby – kogo dokładnie wybieramy i jakie metody konstrukcji próbki stosujemy w tym celu.
- Cechą ilościową próby jest liczba wybranych przypadków, innymi słowy wielkość próby.
Potrzeba pobierania próbek
- Przedmiot badań jest bardzo szeroki. Przykładowo odbiorcami produktów firmy globalnej jest ogromna liczba rynków rozproszonych geograficznie.
- Istnieje potrzeba gromadzenia informacji pierwotnych.
Wielkość próbki
Wielkość próbki- liczba przypadków objętych próbą. Ze względów statystycznych zaleca się, aby liczba przypadków wynosiła co najmniej 30-35.
Próbki zależne i niezależne
Przy porównywaniu dwóch (lub więcej) próbek ważnym parametrem jest ich zależność. Jeżeli uda się ustalić parę homomorficzną (czyli gdy jeden przypadek z próby X odpowiada jednemu i tylko jednemu przypadkowi z próby Y i odwrotnie) dla każdego przypadku w dwóch próbach (i ta podstawa zależności jest istotna dla cechy mierzone w próbkach), próbki takie nazywane są zależny. Przykłady wyborów zależnych:
- para bliźniaków
- dwa pomiary dowolnej cechy przed i po ekspozycji doświadczalnej,
- mężowie i żony
- i tak dalej.
Jeżeli pomiędzy próbkami nie ma takiego związku, wówczas uwzględnia się te próbki niezależny, Na przykład:
W związku z tym próbki zależne mają zawsze tę samą wielkość, natomiast wielkości próbek niezależnych mogą się różnić.
Próbki porównuje się przy użyciu różnych kryteriów statystycznych:
- itd.
Reprezentatywność
Próbkę można uznać za reprezentatywną lub niereprezentatywną.
Przykład próby niereprezentatywnej
- Badanie z grupami eksperymentalnymi i kontrolnymi, które znajdują się w różnych warunkach.
- Badanie z grupami eksperymentalnymi i kontrolnymi, stosując strategię selekcji w parach
- Badanie z wykorzystaniem tylko jednej grupy – eksperymentalnej.
- Badanie z wykorzystaniem planu mieszanego (czynnikowego) – wszystkie grupy umieszczone są w różnych warunkach.
Typy próbek
Próbki dzielą się na dwa typy:
- probabilistyczny
- nieprawdopodobieństwo
Próbki prawdopodobieństwa
- Proste próbkowanie prawdopodobieństwa:
- Proste ponowne próbkowanie. Dobór takiej próby opiera się na założeniu, że każdy respondent ma takie samo prawdopodobieństwo, że znajdzie się w próbie. Na podstawie wykazu populacji ogólnej sporządzane są karty z liczbą respondentów. Umieszcza się je w talii, tasuje i losowo wyjmuje z nich kartę, zapisuje liczbę, a następnie zwraca z powrotem. Ponadto procedurę powtarza się tyle razy, ile potrzebujemy wielkości próbki. Minus: powtarzanie jednostek selekcji.
Procedura konstruowania prostej próbki losowej obejmuje następujące kroki:
1. muszę zdobyć pełna lista członków ogółu populacji i ponumeruj tę listę. Przypomnijmy, taka lista nazywana jest operatem losowania;
2. określić oczekiwaną liczebność próby, czyli oczekiwaną liczbę respondentów;
3. wyodrębnić z tabeli liczb losowych tyle liczb, ile potrzebujemy jednostek próbki. Jeżeli próba ma liczyć 100 osób, z tabeli pobiera się 100 liczb losowych. Te liczby losowe mogą być generowane przez program komputerowy.
4. wybrać z listy bazowej te obserwacje, których numery odpowiadają zapisanym liczbom losowym
- Prosta próbka losowa ma oczywiste zalety. Ta metoda jest niezwykle łatwa do zrozumienia. Wyniki badania można rozszerzyć na badaną populację. Większość podejść do wnioskowania statystycznego obejmuje zbieranie informacji przy użyciu prostej próby losowej. Jednak prosta metoda losowego doboru próby ma co najmniej cztery istotne ograniczenia:
1. Często trudno jest stworzyć operat losowania, który pozwoliłby na pobranie prostej próby losowej.
2. Prosta próbka losowa może skutkować dużą populacją lub populacją rozproszoną na dużym obszarze geograficznym, co znacznie zwiększa czas i koszt gromadzenia danych.
3. Wyniki zastosowania prostej próby losowej charakteryzują się często mniejszą i większą dokładnością Standardowy błąd niż wyniki zastosowania innych metod probabilistycznych.
4. W wyniku zastosowania SRS może powstać próbka niereprezentatywna. Chociaż próbki otrzymane w drodze prostego doboru losowego średnio dobrze reprezentują populację ogólną, niektóre z nich skrajnie błędnie reprezentują badaną populację. Jest to szczególnie prawdopodobne, gdy mała ilość próbki.
- Proste, niepowtarzające się pobieranie próbek. Procedura konstruowania próby jest taka sama, jedynie karty z numerami respondentów nie są zwracane do talii.
- Systematyczne próbkowanie prawdopodobieństwa. Jest to uproszczona wersja prostej próbki prawdopodobieństwa. Na podstawie listy populacji ogólnej w określonym przedziale (K) dobierani są respondenci. Wartość K ustalana jest losowo. Najbardziej wiarygodny wynik uzyskuje się w przypadku jednorodnej populacji ogólnej, w przeciwnym razie wielkość kroku i niektóre wewnętrzne wzorce cykliczne próbki mogą się pokrywać (mieszanie próbek). Wady: takie same jak w prostej próbie prawdopodobieństwa.
- Próbkowanie seryjne (zagnieżdżone). Jednostką próby są szeregi statystyczne (rodzina, szkoła, zespół itp.). Wybrane elementy poddawane są ciągłym badaniom. Dobór jednostek statystycznych można zorganizować według rodzaju losowego lub systematycznego doboru próby. Wady: Możliwość większej jednorodności niż w populacji ogólnej.
- Próbka strefowa. W przypadku populacji heterogenicznej, przed zastosowaniem prób prawdopodobnych dowolną techniką selekcji, zaleca się podzielenie populacji na części jednorodne, próbkę taką nazywamy próbą strefową. Grupy strefowe mogą obejmować zarówno formacje naturalne (na przykład dzielnice miast), jak i dowolny obiekt leżący u podstaw badania. Znak, na podstawie którego przeprowadza się podział, nazywany jest znakiem stratyfikacji i podziału na strefy.
- Wybór „wygodny”. Procedura doboru „wygodnego” polega na nawiązaniu kontaktów z „wygodnymi” jednostkami losowania – z grupą uczniów, drużyną sportową, ze znajomymi i sąsiadami. Jeśli konieczne jest uzyskanie informacji o reakcjach ludzi na nową koncepcję, taka próbka jest całkiem rozsądna. Do wstępnego testowania kwestionariuszy często stosuje się próbkowanie „wygodne”.
Niesamowite próbki
Dobór w takiej próbie nie odbywa się według zasad przypadku, ale według kryteriów subiektywnych – dostępności, typowości, równej reprezentacji itp.
- Dobór kwotowy – dobór budowany jest jako model odtwarzający strukturę populacji ogólnej w postaci kwot (proporcji) badanych cech. Liczbę elementów próby o różnej kombinacji badanych cech ustala się w taki sposób, aby odpowiadała ich udziałowi (proporcji) w populacji ogólnej. Jeśli więc na przykład mamy ogólną populację wynoszącą 5000 osób, w tym 2000 kobiet i 3000 mężczyzn, to w próbie kwotowej będziemy mieli 20 kobiet i 30 mężczyzn lub 200 kobiet i 300 mężczyzn. Próby kwotowe najczęściej opierają się na kryteriach demograficznych: płci, wieku, regionie, dochodach, wykształceniu i innych. Wady: zwykle takie próbki nie są reprezentatywne, ponieważ nie da się uwzględnić kilku parametrów społecznych jednocześnie. Plusy: łatwo dostępny materiał.
- Metoda kuli śnieżnej. Próbka jest zbudowana w następujący sposób. Każdy respondent, zaczynając od pierwszego, proszony jest o kontakt ze swoimi przyjaciółmi, współpracownikami, znajomymi, którzy spełnialiby warunki selekcji i mogliby wziąć udział w badaniu. Zatem, z wyjątkiem pierwszego etapu, próba jest tworzona z udziałem samych obiektów badań. Metodę tę często stosuje się, gdy zachodzi potrzeba odnalezienia i przeprowadzenia wywiadu z trudno dostępnymi grupami respondentów (np. respondenci o wysokich dochodach, respondenci należący do tej samej grupy grupa zawodowa, respondenci mający podobne zainteresowania/pasje itp.)
- Próbkowanie spontaniczne – pobieranie próbek tzw. „pierwszego przybysza”. Często używany w sondażach telewizyjnych i radiowych. Wielkość i skład spontanicznych próbek nie jest z góry znana, a wyznaczany jest tylko przez jeden parametr – aktywność respondentów. Wady: brak możliwości ustalenia, jaką populację reprezentują respondenci, a co za tym idzie brak możliwości określenia reprezentatywności.
- Badanie trasy – często stosowane, jeśli jednostką nauki jest rodzina. Na mapie miejscowość w którym będzie prowadzone badanie, wszystkie ulice są ponumerowane. Za pomocą tabeli (generatora) liczb losowych wybierane są duże liczby. Każdy duża liczba uważa się, że składa się z 3 elementów: numeru ulicy (2-3 pierwsze cyfry), numeru domu, numeru mieszkania. Przykładowo liczba 14832:14 to numer ulicy na mapie, 8 to numer domu, 32 to numer mieszkania.
- Próbkowanie strefowe z selekcją typowych obiektów. Jeżeli po zagospodarowaniu strefowym z każdej grupy zostanie wybrany obiekt typowy, tj. obiekt zbliżony do średniej pod względem większości badanych w badaniu cech, próbkę taką nazywa się strefową z doborem obiektów typowych.
6.Wybór modalny. 7. próbka ekspercka. 8. Próbka heterogeniczna.
Strategie budowania grupy
Wybór grup do udziału w eksperyment psychologiczny realizowany jest przy wykorzystaniu różnych strategii niezbędnych do zapewnienia jak największej zgodności z trafnością wewnętrzną i zewnętrzną.
Randomizacja
Randomizacja, Lub losowy wybór, służy do tworzenia prostych próbek losowych. Stosowanie takiej próby opiera się na założeniu, że każdy członek populacji ma takie samo prawdopodobieństwo, że znajdzie się w próbie. Przykładowo, aby wylosować próbkę 100 studentów uniwersytetu, możesz włożyć do kapelusza kartki papieru z nazwiskami wszystkich studentów uniwersytetu, a następnie wyciągnąć z niej 100 kartek papieru - będzie to wybór losowy (Goodwin J. , s. 147).
Wybór parami
Wybór parami- strategia konstruowania grup próbnych, w której grupy badanych składają się z podmiotów równoważnych pod względem parametrów ubocznych istotnych dla eksperymentu. Strategia ta jest skuteczna w przypadku eksperymentów z wykorzystaniem grup eksperymentalnych i kontrolnych najlepsza opcja- przyciąganie par bliźniaczych (mono- i dizygotycznych), gdyż pozwala na stworzenie...
Selekcja stratometryczna
Selekcja stratometryczna- randomizacja z przydziałem warstw (lub klastrów). Dzięki tej metodzie doboru próby populację ogólną dzieli się na grupy (warstwy) o określonych cechach (płeć, wiek, preferencje polityczne, wykształcenie, poziom dochodów itp.) i wybiera się przedmioty o odpowiednich cechach.
Przybliżone modelowanie
Przybliżone modelowanie- sporządzanie ograniczonych próbek i uogólnianie wniosków na temat tej próby na szerszą populację. Przykładowo, w przypadku udziału w badaniu studentów II roku studiów, dane z tego badania zostają rozszerzone na „osoby w wieku od 17 do 21 lat”. Dopuszczalność takich uogólnień jest niezwykle ograniczona.
Modelowanie przybliżone to utworzenie modelu, który dla jasno określonej klasy systemów (procesów) opisuje swoje zachowanie (lub pożądane zjawiska) z akceptowalną dokładnością.
Notatki
Literatura
Nasledov A. D. Matematyczne metody badań psychologicznych. - Petersburg: Przemówienie, 2004.
- Ilyasov F. N. Reprezentatywność wyników ankiety w badaniach marketingowych Sotsiologicheskie issledovaniya. 2011. nr 3. s. 112-116.
Zobacz też
- W niektórych typach badań próba jest dzielona na grupy:
- eksperymentalny
- kontrola
- Kohorta
Spinki do mankietów
- Pojęcie pobierania próbek. Główne cechy próbki. Typy próbek
Fundacja Wikimedia. 2010 .
Synonimy:Zobacz, co oznacza „Wybór” w innych słownikach:
próbka- grupa osób reprezentująca określoną populację i wybrana do eksperymentu lub badania. Koncepcja przeciwna to całość ogółu. Próba jest częścią populacji ogólnej. Słownik psychologa praktycznego. M.: AST, ... ... Wielka encyklopedia psychologiczna
próbka- próbkowanie Część ogólnej populacji elementów objęta obserwacją (często nazywana populacją próbkującą, a próbka jest samą metodą obserwacji próbkowania). W statystyce matematycznej przyjmuje się ... ... Podręcznik tłumacza technicznego
- (próbka) 1. Mała ilość towaru wybrana tak, aby reprezentowała całą jego ilość. Zobacz: sprzedaż próbna. 2. Niewielka ilość produktu przekazywana potencjalnym nabywcom, aby dać im możliwość wydania go... ... Słowniczek terminów biznesowych
Próbka- część ogólnej populacji elementów objęta obserwacją (często nazywana jest populacją próbną, a sama próba jest metodą obserwacji selektywnej). W statystyce matematycznej przyjmuje się zasadę doboru losowego; Ten… … Słownik ekonomiczno-matematyczny
- (próbka) Losowy wybór podgrupy elementów z populacji głównej, których cechy służą do oceny całej populacji jako całości. Próbkowanie stosuje się, gdy badanie całej populacji jest zbyt długie lub zbyt kosztowne... Słownik ekonomiczny
Cm … Słownik synonimów
Empiryczne są uważane za jeden z głównych sposobów badania relacji i procesów społecznych. Dostarczają rzetelnych, pełnych i reprezentatywnych informacji.
Specyfika technik
Empiryczne zapewniają uzyskanie wiedzy ustalającej fakty. Przyczyniają się do ustalenia i uogólnienia okoliczności poprzez pośrednią lub bezpośrednią rejestrację zdarzeń tkwiących w badanych relacjach, przedmiotach, zjawiskach. Metody empiryczne różnią się od teoretycznych tym, że przedmiotem analizy są:
- Zachowanie jednostek i ich grup.
- Produkty działalności człowieka.
- Werbalne działania jednostek, ich sądy, poglądy, opinie.
Przykładowe badania
Badania empiryczne zawsze skupiają się na uzyskaniu obiektywnych i dokładnych informacji, danych ilościowych. W związku z tym podczas przeprowadzania należy zapewnić reprezentatywność informacji. W związku z tym prawidłowe zestaw próbek. Ten Oznacza to, że selekcja musi być przeprowadzona w taki sposób, aby dane uzyskane z wąskiej grupy odzwierciedlały tendencje, jakie zachodzą w ogólnej masie respondentów. Na przykład, przeprowadzając wywiady z 200-300 osobami, uzyskane dane można ekstrapolować na wszystkich populacja miejska. Wskaźniki próby pozwalają na odmienne podejście do badania procesów społeczno-gospodarczych w regionie, w skali kraju.

Terminologia
Aby lepiej zrozumieć zagadnienia związane z badaniami reprezentacyjnymi, należy doprecyzować niektóre definicje. Jednostka obserwacji jest bezpośrednim źródłem informacji. Może to być osoba fizyczna, grupa, dokument, organizacja itd. Ogólna populacja jest zestaw jednostek obserwacyjnych. Wszystkie powinny mieć związek z badanym problemem. podlega bezpośredniej analizie. Badanie prowadzone jest zgodnie z opracowanymi metodami gromadzenia informacji. Aby określić tę proporcję całej tablicy respondentów, użyj pojęcie „próbki”. Jego właściwość odzwierciedlania kluczowych parametrów całkowitej masy ludzi nazywa się reprezentatywnością. W niektórych przypadkach nie ma dopasowań. Mówi się wówczas o błędzie reprezentatywności.
Zapewnienie reprezentatywności
Zagadnienia z tym związane są szczegółowo rozpatrywane w ramach statystyki. Problemy są złożone, ponieważ z jednej strony mówimy o zapewnieniu reprezentacji ilościowej, która daje ogółu społeczeństwa. Ten oznacza w szczególności, że grupy respondentów powinny być reprezentowane w optymalnej liczbie. Ilość musi być wystarczająca do normalnego przedstawienia. Z drugiej strony oznacza to także reprezentację jakościową. Zakłada pewną kompozycję tematyczną, która się tworzy zestaw próbek. Ten oznacza, że na przykład nie można omawiać reprezentatywności, jeśli wywiady przeprowadzane są wyłącznie z mężczyznami lub kobietami, osobami starszymi lub młodymi. Badanie należy przeprowadzić w obrębie wszystkich reprezentowanych grup.

Przykładowa charakterystyka
Termin ten rozpatrywany jest w dwóch aspektach. Przede wszystkim definiuje się go jako zespół elementów z ogólnego kręgu osób, których opinia jest badana - to jest zestaw próbek. Ten także proces tworzenia określonej kategorii respondentów o wymaganej reprezentatywności. W praktyce istnieje kilka rodzajów i typów selekcji. Rozważmy je.
Typy
Są trzy z nich:
- spontaniczny zestaw próbek. Ten grupa respondentów wybrana na zasadzie dobrowolności. Jednocześnie zapewniona jest dostępność występowania jednostek z ogólnej masy osób w określonej grupie badawczej. Dobór spontaniczny w praktyce jest stosowany dość często. Na przykład w ankietach w prasie, pocztą. Jednak to podejście ma istotną wadę. Niemożliwe jest jakościowe przedstawienie całej objętości próbki ogólnej. Technikę tę stosuje się ze względu na ekonomię. W niektórych ankietach ta opcja jest jedyną możliwą.
- spontaniczny zestaw próbek. Ten jedna z głównych metod stosowanych w badaniu. Kluczową zasadą takiej selekcji jest zapewnienie każdej jednostce obserwacji możliwości przedostania się z ogólnej masy jednostek do wąskiej grupy. W tym celu stosuje się różne metody. Może to być na przykład loteria, selekcja mechaniczna, tabela liczb losowych.
- Próbkowanie warstwowe (kwotowe). Opiera się na formacji model jakościłączna liczba respondentów. Następnie przeprowadzany jest dobór jednostek w populacji próbnej. Na przykład przeprowadza się go według wieku lub płci, według grup populacji i tak dalej.
Rodzaje
Dostępne są następujące opcje:

Dodatkowo
Próbki mogą być również zależne i niezależne. W pierwszym przypadku przebieg eksperymentu i wyniki, jakie w jego trakcie zostaną uzyskane dla jednej grupy respondentów, mają pewien wpływ na drugą. W związku z tym niezależne próbki nie oznaczają takiego wpływu. Tutaj jednak warto zwrócić uwagę na jedno ważny punkt. Za osobę zależną domyślnie będzie uznawana grupa osób, wobec której dwukrotnie przeprowadzono badanie psychologiczne (nawet jeśli miało ono na celu zbadanie różnych cech, cech, cech).
Wybory probabilistyczne
Rozważ niektóre typy próbek:
- Losowy. Zakłada jednorodność całej populacji, jedno prawdopodobieństwo dostępności wszystkich składników, a także obecność pełnej listy elementów. Z reguły proces selekcji wykorzystuje tabelę z losowe liczby.
- Mechaniczny. Ten rodzaj losowego pobierania próbek polega na uporządkowaniu według określonej cechy. Na przykład według numeru telefonu, alfabetycznie, według daty urodzenia i tak dalej. Pierwszy składnik jest wybierany losowo. Następnie każdy element k jest wybierany w kroku n. Wartość całej populacji będzie wynosić N=k*n.
- Warstwowy. Próbkę tę stosuje się, gdy całkowita populacja jest niejednorodna. Ten ostatni dzieli się na warstwy (grupy). W każdym z nich selekcja odbywa się mechanicznie lub losowo.
- Seryjny. Grupy dobierane są losowo. Wewnątrz nich obiekty są badane przez cały czas.
Niesamowite wybory
Polegają one na próbkowaniu nie na podstawie losowości, ale na podstawie subiektywnych kryteriów: typowości, dostępności, równej reprezentacji i tak dalej. Do wyboru w tej kategorii należą:

Niuans
Aby zapewnić reprezentatywność, potrzebny jest dokładny i kompletny wykaz jednostek populacji. Obiektem obserwacji jest z reguły jedna osoba. Wyboru z listy najlepiej dokonać numerując jednostki i korzystając z tabeli z liczbami losowymi. Często jednak stosowana jest również metoda quasi-losowa. Zakłada wybór z listy każdego n elementu.
Czynniki wpływające
Objętość populacji to liczba jej jednostek. Według ekspertów nie musi być duży. Niewątpliwie niż więcej numeru respondentów, tym dokładniejszy jest wynik. Jednak jednocześnie duży wolumen nie zawsze gwarantuje sukces. Dzieje się tak na przykład wtedy, gdy całkowita grupa respondentów jest niejednorodna. Za jednorodny będzie uważany taki zbiór, gdzie kontrolowany parametr na przykład poziom umiejętności czytania i pisania rozkłada się równomiernie, to znaczy nie ma pustek ani kondensacji. W tym przypadku wystarczy przeprowadzić wywiad z kilkoma osobami. Na podstawie wyników badania można stwierdzić, że większość ludzie mają normalny poziom alfabetyzacja. Wynika z tego, że na reprezentatywność informacji wpływają nie cechy ilościowe, ale: cechy jakościowe kruszywo – w szczególności stopień jego jednorodności.

Błędy
Stanowią one odchylenie średnich parametrów populacji próby od wartości całkowitej masy respondentów. W praktyce błędy są określane poprzez dopasowanie. Przy badaniu osób dorosłych zwykle wykorzystuje się dane ze spisów powszechnych, dane statystyczne i wyniki wcześniejszych badań. Parametry kontrolne to zazwyczaj porównanie średnich wartości populacji (ogólnej i próbnej), określenie błędu zgodnie z tym i zmniejszenie tego odchylenia nazywa się kontrolą reprezentatywności.
wnioski
Badania reprezentacyjne to sposób gromadzenia danych na temat postaw i zachowań ludzi poprzez badanie ankietowe specjalnie wybranych grup respondentów. Technika ta jest uważana za niezawodną i ekonomiczną, chociaż wymaga określonej techniki. Próbka to podstawa. Działa jako pewna część całkowitej masy ludzi. Selekcja dokonywana jest przy użyciu specjalnych technik i ma na celu uzyskanie informacji o całej populacji. Ten ostatni z kolei jest reprezentowany przez wszystkie możliwe obiekty społeczne lub przez grupę, która będzie badana. Często populacja jest tak duża, że przeprowadzenie badania każdego jej członka byłoby dość kosztowne i kłopotliwe. Dlatego stosuje się model zredukowany. Próba obejmuje wszystkich, którzy otrzymują kwestionariusze, nazywani respondentami, którzy w rzeczywistości są przedmiotem badań. Mówiąc najprościej, składa się z wielu osób, z którymi przeprowadza się wywiady.

Wniosek
Cele badania wyznaczane są przez konkretne kategorie wchodzące w skład populacji. Jeśli chodzi o określony udział w ogólnej masie ludzi, tworzą go podmioty zaliczane do grup stosujących obliczenia matematyczne. Do doboru jednostek niezbędny jest opis obiektu populacji początkowej. Po ustaleniu liczby osób ustala się recepcję lub sposób tworzenia grup. Wyniki badania pozwolą nam opisać badaną cechę w odniesieniu do wszystkich przedstawicieli ogólnej masy ludzi. Jak pokazuje praktyka, prowadzone są głównie badania selektywne, a nie ciągłe.
Populacja- zbiór jednostek, który ma charakter masowy, typowość, jednolitość jakościową i obecność zmienności.
Populacja statystyczna składa się z obiektów istniejących materialnie (Pracownicy, przedsiębiorstwa, kraje, regiony), jest przedmiotem.
Jednostka populacji- każda konkretna jednostka populacji statystycznej.
Jedna i ta sama populacja statystyczna może być jednorodna pod względem jednej cechy i niejednorodna pod względem innej.
Jednolitość jakościowa- podobieństwo wszystkich jednostek populacji pod względem dowolnej cechy i odmienność dla wszystkich pozostałych.
W populacji statystycznej różnice pomiędzy jedną jednostką populacji a drugą mają częściej charakter ilościowy. Ilościowe zmiany wartości atrybutu różnych jednostek populacji nazywane są zmiennością.
Odmiana funkcji- ilościowa zmiana znaku (dla znaku ilościowego) podczas przejścia z jednej jednostki populacji do drugiej.
podpisać jest własnością Charakterystyka lub inna cecha jednostek, obiektów i zjawisk, którą można zaobserwować lub zmierzyć. Znaki dzielą się na ilościowe i jakościowe. Nazywa się zróżnicowanie i zmienność wartości cechy w poszczególnych jednostkach populacji zmiana.
Cechy atrybutywne (jakościowe) nie są wymierne (skład populacji według płci). Charakterystyka ilościowa ma wyraz liczbowy (skład populacji według wieku).
Indeks- jest to uogólniająca cecha ilościowa i jakościowa dowolnej właściwości jednostek lub agregatów przeznaczona do określonego celu w określonych warunkach czasu i miejsca.
Karta z punktami to zbiór wskaźników kompleksowo odzwierciedlających badane zjawisko.
Rozważmy na przykład wynagrodzenie:- Znak - płace
- Populacja statystyczna – wszyscy pracownicy
- Jednostką populacji jest każdy robotnik
- Jednorodność jakościowa - naliczone wynagrodzenie
- Wariacja cechy - ciąg liczb
Populacja ogólna i próbka z niej
Podstawą jest zbiór danych uzyskanych w wyniku pomiaru jednej lub większej liczby cech. Naprawdę obserwowany zbiór obiektów, statystycznie reprezentowany przez serię obserwacji zmienna losowa, Jest próbowanie, i hipotetycznie istniejące (przemyślane) - ogólna populacja. Populacja ogólna może być skończona (liczba obserwacji N = stała) lub nieskończone ( N = ∞), a próba z populacji ogólnej jest zawsze wynikiem ograniczonej liczby obserwacji. Liczba obserwacji tworzących próbkę nazywa się wielkość próbki. Jeśli wielkość próbki jest wystarczająco duża n → ∞) próbka jest brana pod uwagę duży w przeciwnym razie nazywa się to próbką ograniczona objętość. Próbka jest brana pod uwagę mały, jeżeli przy pomiarze jednowymiarowej zmiennej losowej liczebność próby nie przekracza 30 ( N<= 30 ), a przy jednoczesnym pomiarze kilku ( k) cechy w wielowymiarowej relacji przestrzennej N Do k nie przekracza 10 (nr< 10) . Przykładowe formularze seria odmian jeśli są jej członkowie statystyki zamówień, czyli przykładowe wartości zmiennej losowej X sortowane są w kolejności rosnącej (rankingowej), wywoływane są wartości atrybutu opcje.
Przykład. Prawie ten sam losowo wybrany zestaw obiektów - banki komercyjne jednego okręgu administracyjnego Moskwy, można uznać za próbę z ogólnej populacji wszystkich banków komercyjnych w tym okręgu oraz jako próbę z ogólnej populacji wszystkich banków komercyjnych w Moskwie , a także próbkę banków komercyjnych w kraju itp.
Podstawowe metody pobierania próbek
Wiarygodność wniosków statystycznych i miarodajna interpretacja wyników zależy od reprezentatywność próbki, tj. kompletność i adekwatność reprezentacji cech populacji ogólnej, w odniesieniu do której tę próbę można uznać za reprezentatywną. Badanie właściwości statystycznych populacji można zorganizować na dwa sposoby: za pomocą ciągły I nieciągły. Ciągła obserwacja obejmuje badanie wszystkich jednostki badane agregaty, A obserwacja nieciągła (selektywna).- tylko jego części.
Istnieje pięć głównych sposobów organizacji pobierania próbek:
1. prosty losowy wybór, w którym obiekty są wybierane losowo z ogólnej populacji obiektów (na przykład za pomocą tabeli lub generatora liczb losowych), a każda z możliwych próbek ma równe prawdopodobieństwo. Takie próbki nazywane są faktycznie losowe;
2. prosty wybór w drodze zwykłej procedury przeprowadza się za pomocą elementu mechanicznego (na przykład dat, dni tygodnia, numerów mieszkań, liter alfabetu itp.), a uzyskane w ten sposób próbki nazywane są mechaniczny;
3. warstwowy selekcja polega na tym, że ogólna populacja objętości jest podzielona na podzbiory lub warstwy (warstwy) objętości w taki sposób, że . Warstwy są obiektami jednorodnymi pod względem cech statystycznych (np. populacja jest podzielona na warstwy według grupy wiekowej lub klasy społecznej; przedsiębiorstwa według branży). W takim przypadku próbki nazywane są warstwowy(W przeciwnym razie, warstwowy, typowy, strefowy);
4. metody seryjny selekcja służy do formowania seryjny Lub próbki zagnieżdżone. Są wygodne, jeśli konieczne jest jednoczesne zbadanie „bloku” lub serii obiektów (na przykład przesyłki towarów, produktów określonej serii lub ludności w podziale terytorialno-administracyjnym kraju). Wybór serii może odbywać się w sposób losowy lub mechaniczny. Jednocześnie przeprowadza się ciągłe badanie określonej partii towaru lub całej jednostki terytorialnej (budynku mieszkalnego lub dzielnicy);
5. łączny selekcja (stopniowa) może łączyć kilka metod selekcji jednocześnie (na przykład warstwową i losową lub losową i mechaniczną); taka próbka nazywa się łączny.
Typy selekcji
Przez umysł istnieje selekcja indywidualna, grupowa i łączona. Na indywidualny wybór do zbioru próby dobierane są poszczególne jednostki populacji ogólnej, przy czym wybór grupy są jakościowo jednorodnymi grupami (seriami) jednostek, oraz łączony wybór obejmuje kombinację pierwszego i drugiego typu.
Przez metoda wybór rozróżnia powtarzalne i nie powtarzalne próbka.
Niepowtarzalny zwana selekcją, w której jednostka, która wpadła do próby, nie wraca do populacji pierwotnej i nie bierze udziału w dalszej selekcji; natomiast liczba jednostek populacji ogólnej N zmniejszona w procesie selekcji. Na powtarzający się wybór złapany w próbie jednostka po rejestracji wraca do populacji ogólnej, zachowując tym samym równe szanse, wraz z innymi jednostkami, do wykorzystania w dalszej procedurze selekcji; natomiast liczba jednostek populacji ogólnej N pozostaje niezmieniona (metoda jest rzadko stosowana w badaniach społeczno-ekonomicznych). Jednak z dużym N (N → ∞) formuły dla niepowtórzone wybór jest zbliżony do tych dla powtarzający się selekcji, przy czym te drugie są stosowane niemal częściej ( N = stała).
Główne cechy parametrów populacji ogólnej i próbnej
Podstawą wniosków statystycznych z badania jest rozkład zmiennej losowej, natomiast obserwowane wartości (x 1, x 2, ..., x n) nazywane są realizacjami zmiennej losowej X(n to wielkość próbki). Rozkład zmiennej losowej w populacji ogólnej jest teoretyczny, ma charakter idealny, podobnie jak jej odpowiednik w próbie empiryczny dystrybucja. Niektóre rozkłady teoretyczne podaje się analitycznie, tj. ich opcje określić wartość funkcji rozkładu w każdym punkcie przestrzeni możliwych wartości zmiennej losowej. Dlatego w przypadku próbki określenie funkcji rozkładu jest trudne, a czasem niemożliwe opcje są szacowane na podstawie danych empirycznych, a następnie podstawione do wyrażenia analitycznego opisującego rozkład teoretyczny. W tym przypadku założenie (lub hipoteza) na temat rodzaju rozkładu może być zarówno statystycznie poprawne, jak i błędne. W każdym razie rozkład empiryczny zrekonstruowany na podstawie próbki tylko w przybliżeniu charakteryzuje rozkład prawdziwy. Najważniejszymi parametrami dystrybucji są wartość oczekiwana i dyspersja.
Dystrybucje są ze swej natury ciągły I oddzielny. Najbardziej znaną dystrybucją ciągłą jest normalna. Selektywne analogie parametrów i dla niego to: wartość średnia i wariancja empiryczna. Wśród dyskretnych w badaniach społeczno-ekonomicznych, najczęściej stosowanych alternatywa (dychotomiczna) dystrybucja. Parametr oczekiwań tego rozkładu wyraża wartość względną (lub udział) jednostki populacji posiadające badaną cechę (jest to oznaczone literą ); odsetek populacji, który nie posiada tej cechy, jest oznaczony literą q (q = 1 - p). Wariancja alternatywnego rozkładu ma również empiryczny odpowiednik.
W zależności od rodzaju rozkładu i sposobu doboru jednostek populacji, charakterystyki parametrów rozkładu obliczane są w różny sposób. Główne rozkłady teoretyczne i empiryczne podano w tabeli. 9.1.
Przykładowy udział k n to stosunek liczby jednostek populacji próbnej do liczby jednostek populacji ogólnej:
kn = n/N.
Przykładowy udział w to stosunek jednostek mających badaną cechę X do wielkości próbki N:
w = n n / n.
Przykład. W partii towaru zawierającej 1000 sztuk, przy próbie 5%. frakcja próbki k n w wartości bezwzględnej wynosi 50 jednostek. (n = N*0,05); jeśli w tej próbce zostaną znalezione 2 wadliwe produkty, wówczas frakcja próbki w wyniesie 0,04 (w = 2/50 = 0,04 lub 4%).
Ponieważ populacja próbna różni się od populacji ogólnej, istnieją błędy próbkowania.
Tabela 9.1 Główne parametry populacji ogólnej i próbnej
Błędy próbkowania
Przy każdym (solidnym i selektywnym) błędach mogą wystąpić dwa rodzaje: rejestracja i reprezentatywność. Błędy rejestracja może mieć losowy I systematyczny postać. Losowy błędy powstają z wielu różnych, niekontrolowanych przyczyn, mają charakter niezamierzony i zwykle równoważą się wzajemnie (na przykład zmiany odczytów przyrządów spowodowane wahaniami temperatury w pomieszczeniu).
Systematyczny błędy są stronnicze, ponieważ naruszają zasady doboru obiektów do próbki (na przykład odchylenia w pomiarach przy zmianie ustawień urządzenia pomiarowego).
Przykład. Aby ocenić status społeczny ludności miasta, planuje się przebadać 25% rodzin. Jeżeli jednak wybór co czwartego mieszkania opierać się będzie na jego liczbie, wówczas istnieje niebezpieczeństwo wybrania wszystkich mieszkań tylko jednego typu (np. mieszkania jednopokojowe), co wprowadzi błąd systematyczny i zafałszuje wyniki; bardziej preferowany jest losowy wybór numeru mieszkania, ponieważ błąd będzie losowy.
Błędy reprezentatywności nieodłącznie związane jedynie z obserwacją selektywną, nie da się ich uniknąć i powstają na skutek tego, że próbka nie w pełni odtwarza próbkę ogólną. Wartości wskaźników uzyskane z próby różnią się od wskaźników o tych samych wartościach w populacji ogólnej (lub uzyskanych podczas obserwacji ciągłej).
Błąd próbkowania jest różnicą między wartością parametru w populacji ogólnej a wartością w próbce. Dla średniej wartości atrybutu ilościowego jest ona równa: , a dla udziału (atrybutu alternatywnego) - .
Błędy próbkowania są nieodłącznie związane tylko z obserwacjami próbek. Im większe są te błędy, tym bardziej rozkład empiryczny różni się od teoretycznego. Parametry rozkładu empirycznego i są zmiennymi losowymi, dlatego błędy próbkowania są również zmiennymi losowymi, mogą przyjmować różne wartości dla różnych próbek i dlatego zwyczajowo oblicza się średni błąd.
Średni błąd próbkowania jest wartością wyrażającą odchylenie standardowe średniej próbki od oczekiwań matematycznych. Wartość ta, z zastrzeżeniem zasady doboru losowego, zależy przede wszystkim od liczebności próby oraz od stopnia zmienności cechy: im większe i im mniejsze jest zmienność cechy (stąd wartość ), tym mniejsza jest wartość średni błąd próbkowania. Stosunek wariancji populacji ogólnej i próbnej wyraża się wzorem:
te. dla wystarczająco dużych, możemy założyć, że . Średni błąd próbkowania pokazuje możliwe odchylenia parametru populacji próbnej od parametru populacji ogólnej. W tabeli. 9.2 pokazuje wyrażenia do obliczania średniego błędu próbkowania dla różnych metod organizacji obserwacji.
Tabela 9.2 Średni błąd (m) średniej próbki i proporcji dla różnych typów próbek
Gdzie jest średnią wariancji próbki wewnątrzgrupowej dla cechy ciągłej;
Średnia dyspersji wewnątrzgrupowych udziału;
— liczba wybranych serii, — całkowita liczba serii;
 ,
,
gdzie jest średnia serii th;
- ogólna średnia z całej próbki dla cechy ciągłej;
 ,
,
gdzie jest proporcja cechy w szeregu th;
— całkowity udział cechy w całej próbie.
Jednakże wielkość średniego błędu można ocenić jedynie z pewnym prawdopodobieństwem Р (Р ≤ 1). Lapunow A.M. udowodnili, że rozkład średnich z próby, a co za tym idzie ich odchylenia od średniej ogólnej, przy dostatecznie dużej liczbie, w przybliżeniu jest zgodny z prawem rozkładu normalnego, pod warunkiem, że populacja ogólna ma skończoną średnią i ograniczoną wariancję.
Matematycznie to stwierdzenie dotyczące średniej wyraża się jako:

a dla ułamka wyrażenie (1) będzie miało postać:
Gdzie  -
Jest marginalny błąd próbkowania, który jest wielokrotnością średniego błędu próbkowania ,
a współczynnikiem krotności jest kryterium Studenta („współczynnik ufności”) zaproponowane przez W.S. Gosset (pseudonim „Student”); wartości dla różnych wielkości próbek są przechowywane w specjalnej tabeli.
-
Jest marginalny błąd próbkowania, który jest wielokrotnością średniego błędu próbkowania ,
a współczynnikiem krotności jest kryterium Studenta („współczynnik ufności”) zaproponowane przez W.S. Gosset (pseudonim „Student”); wartości dla różnych wielkości próbek są przechowywane w specjalnej tabeli.

Dlatego wyrażenie (3) można odczytać następująco: z prawdopodobieństwem P = 0,683 (68,3%) można argumentować, że różnica między próbą a średnią ogólną nie przekroczy jednej wartości błędu średniego m(t=1), z prawdopodobieństwem P = 0,954 (95,4%)— aby nie przekraczała wartości dwóch błędów średnich m (t = 2) , z prawdopodobieństwem P = 0,997 (99,7%)- nie przekroczy trzech wartości m (t = 3) . Określa się zatem prawdopodobieństwo, że różnica ta przekroczy trzykrotność wartości błędu średniego poziom błędu i nie jest więcej niż 0,3% .
W tabeli. 9.3 Podano wzory na obliczenie krańcowego błędu próbkowania.
Tabela 9.3 Marginalny błąd próbkowania (D) dla średniej i proporcji (p) dla różnych typów próbkowania
Rozszerzanie wyników próby na populację
Ostatecznym celem obserwacji próby jest scharakteryzowanie populacji ogólnej. W przypadku małych próbek empiryczne szacunki parametrów ( i ) mogą znacznie odbiegać od ich prawdziwych wartości ( i ). Dlatego konieczne staje się ustalenie granic, w których dla przykładowych wartości parametrów ( i ) leżą prawdziwe wartości ( i ).
Przedział ufności pewnego parametru θ populacji ogólnej nazywany jest losowym zakresem wartości tego parametru, który z prawdopodobieństwem bliskim 1 ( niezawodność) zawiera prawdziwą wartość tego parametru.
błąd marginalny próbki Δ pozwala określić wartości graniczne cech populacji ogólnej i ich przedziały ufności, które są równe:
Konkluzja przedział ufności otrzymane przez odejmowanie błąd marginalny ze średniej próbki (udziału) i od góry, dodając ją.
Przedział ufności dla średniej wykorzystuje się marginalny błąd próbkowania i dla danego poziomu ufności wyznacza się ze wzoru:
Oznacza to, że z danym prawdopodobieństwem R, który nazywany jest poziomem ufności i jest jednoznacznie określany przez wartość T, można argumentować, że prawdziwa wartość średniej mieści się w przedziale od ![]() , a prawdziwa wartość udziału mieści się w przedziale od
, a prawdziwa wartość udziału mieści się w przedziale od
Przy obliczaniu przedziału ufności dla trzech standardowych poziomów ufności P=95%, P=99% i P=99,9% wartość jest wybierana przez . Zastosowania w zależności od liczby stopni swobody. Jeśli wielkość próbki jest wystarczająco duża, wówczas wartości odpowiadają tym prawdopodobieństwu T są równe: 1,96, 2,58 I 3,29 . Zatem marginalny błąd próbkowania pozwala nam wyznaczyć wartości krańcowe cech populacji ogólnej i ich przedziały ufności:
Rozkład wyników obserwacji selektywnej na populację ogólną w badaniach społeczno-ekonomicznych ma swoją specyfikę, wymaga bowiem kompletności reprezentatywności wszystkich jej typów i grup. Podstawą możliwości takiego podziału jest kalkulacja względny błąd:

Gdzie Δ % - względny marginalny błąd próbkowania; , .
Istnieją dwie główne metody rozszerzania obserwacji próby na populację: przeliczenie bezpośrednie i metoda współczynników.
Istota bezpośrednia konwersja polega na pomnożeniu średniej próbki!!\overline(x) przez wielkość populacji.
Przykład. Niech metodą losowania oszacujemy średnią liczbę małych dzieci w mieście i wyniesiemy ją na osobę. Jeżeli w mieście jest 1000 młodych rodzin, liczbę potrzebnych miejsc w żłobku miejskim oblicza się mnożąc tę średnią przez liczebność populacji ogólnej N = 1000, tj. będzie 1200 miejsc.
Metoda współczynników wskazane jest stosowanie w przypadku prowadzenia obserwacji selektywnej w celu doprecyzowania danych z obserwacji ciągłej.
Używa się przy tym wzoru:
gdzie wszystkie zmienne to wielkość populacji:
Wymagana wielkość próbki
Tabela 9.4 Wymagana liczebność próby (n) dla różnych typów organizacji pobierających próbki
Planując badanie losowe z ustaloną wartością dopuszczalnego błędu próbkowania, konieczne jest prawidłowe oszacowanie wymaganego wielkość próbki. Wielkość tę można wyznaczyć na podstawie błędu dopuszczalnego podczas obserwacji selektywnej, opartej na zadanym prawdopodobieństwie gwarantującym akceptowalny poziom błędu (biorąc pod uwagę sposób organizacji obserwacji). Wzory na określenie wymaganej wielkości próby n można łatwo uzyskać bezpośrednio ze wzorów na marginalny błąd próbkowania. Zatem z wyrażenia na błąd krańcowy:
wielkość próbki jest określana bezpośrednio N:
Wzór ten pokazuje, że wraz ze zmniejszaniem się marginalnego błędu próbkowania Δ znacząco zwiększa wymaganą liczebność próby, która jest proporcjonalna do wariancji i kwadratu testu t-Studenta.
Dla określonego sposobu organizacji obserwacji wymaganą liczebność próby oblicza się według wzorów podanych w tabeli. 9.4.
Praktyczne przykłady obliczeń
Przykład 1. Obliczenie wartości średniej i przedziału ufności dla ciągłej charakterystyki ilościowej.
Aby ocenić szybkość rozliczeń z wierzycielami w banku, przeprowadzono losową próbę 10 dokumentów płatniczych. Ich wartości okazały się równe (w dniach): 10; 3; 15; 15; 22; 7; 8; 1; 19; 20.
Wymagane z prawdopodobieństwem P = 0,954 określić błąd marginalny Δ średnia próbki i granice ufności średniego czasu obliczeń.
Rozwiązanie. Wartość średnią oblicza się według wzoru z tabeli. 9.1 dla próbki populacji
![]()
Dyspersję oblicza się według wzoru z tabeli. 9.1.
![]()
Średni błąd kwadratowy dnia.
Błąd średniej oblicza się ze wzoru:
![]()
te. średnia wartość wynosi x ± m = 12,0 ± 2,3 dni.
Rzetelność średniej była
![]()
Błąd graniczny oblicza się ze wzoru z tabeli. 9.3 do ponownej selekcji, ponieważ wielkość populacji nie jest znana, i dla P = 0,954 poziom zaufania.
Zatem średnia wartość wynosi `x ± D = `x ± 2m = 12,0 ± 4,6, tj. jego rzeczywista wartość mieści się w przedziale od 7,4 do 16,6 dnia.
Korzystanie ze stołu ucznia. Aplikacja pozwala stwierdzić, że dla n = 10 – 1 = 9 stopni swobody otrzymana wartość jest wiarygodna przy poziomie istotności a 0,001 £, tj. uzyskana wartość średnia jest znacząco różna od 0.
Przykład 2. Oszacowanie prawdopodobieństwa (ogólnego udziału) r.
Dzięki mechanicznej metodzie doboru próby, polegającej na badaniu statusu społecznego 1000 rodzin, okazało się, że odsetek rodzin o niskich dochodach był w = 0,3 (30%)(próbka była 2% , tj. n/N = 0,02). Wymagane przy poziomie ufności p = 0,997 zdefiniuj wskaźnik R rodzin o niskich dochodach w całym regionie.
Rozwiązanie. Według przedstawionych wartości funkcji Ф(t) znaleźć dla danego poziomu ufności P = 0,997 oznaczający t=3(patrz wzór 3). Marginalny błąd udziału w określić na podstawie wzoru z tabeli. 9.3 dla pobierania próbek jednorazowych (pobieranie mechaniczne jest zawsze jednorazowe):
Graniczny względny błąd próbkowania w % będzie:
Prawdopodobieństwo (ogólny udział) rodzin o niskich dochodach w regionie będzie wynosić p=w±Δw, a granice ufności p oblicza się na podstawie podwójnej nierówności:
w — Δw ≤ p ≤ w — Δw, tj. prawdziwa wartość p leży w:
0,3 — 0,014 < p <0,3 + 0,014, а именно от 28,6% до 31,4%.
Zatem z prawdopodobieństwem 0,997 można stwierdzić, że odsetek rodzin o niskich dochodach wśród wszystkich rodzin w województwie waha się od 28,6% do 31,4%.
Przykład 3 Obliczenie wartości średniej i przedziału ufności dla cechy dyskretnej określonej szeregiem przedziałów.
W tabeli. 9,5. ustala się podział wniosków o produkcję zamówień według terminu ich realizacji przez przedsiębiorstwo.
Tabela 9.5 Rozkład obserwacji według czasu wystąpieniaRozwiązanie. Średni czas realizacji zamówienia obliczany jest według wzoru:
Średni czas będzie wynosić:
= (3*20 + 9*80 + 24*60 + 48*20 + 72*20)/200 = 23,1 miesiąca
Tę samą odpowiedź otrzymamy, jeśli wykorzystamy dane dotyczące p i z przedostatniej kolumny tabeli. 9.5 korzystając ze wzoru:
Należy zauważyć, że środek przedziału ostatniej gradacji znajduje się poprzez sztuczne uzupełnienie go o szerokość przedziału poprzedniej gradacji równą 60 - 36 = 24 miesiące.
Dyspersję oblicza się ze wzoru
![]()
Gdzie x ja- środek serii interwałowej.
Zatem!!\sigma = \frac (20^2 + 14^2 + 1 + 25^2 + 49^2)(4) i błąd standardowy wynosi .
Błąd średniej oblicza się ze wzoru na miesiące, tj. średnia wynosi!!\overline(x) ± m = 23,1 ± 13,4.
Błąd graniczny oblicza się ze wzoru z tabeli. 9.3 do ponownej selekcji, ponieważ wielkość populacji jest nieznana, dla poziomu ufności 0,954:
Zatem średnia wynosi:
te. jego prawdziwa wartość mieści się w przedziale od 0 do 50 miesięcy.
Przykład 4 Aby określić szybkość rozliczeń z wierzycielami N = 500 przedsiębiorstw korporacji w banku komercyjnym, konieczne jest przeprowadzenie badania selektywnego metodą losowej, jednorazowej selekcji. Wyznacz wymaganą liczebność próby n tak, aby z prawdopodobieństwem P = 0,954 błąd średniej próby nie przekraczał 3 dni, jeżeli szacunki próbne wykazały, że odchylenie standardowe s wynosiło 10 dni.
Rozwiązanie. Aby określić liczbę wymaganych badań n, korzystamy ze wzoru na jednorazowy wybór z tabeli. 9.4:

W nim wartość t wyznacza się z poziomu ufności Р = 0,954. Jest ona równa 2. Średnia wartość kwadratowa s = 10, liczebność populacji N = 500 i błąd krańcowy średniej Δ x = 3. Podstawiając te wartości do wzoru, otrzymujemy:
![]()
te. wystarczy dokonać próby 41 przedsiębiorstw, aby oszacować wymagany parametr – szybkość ugód z wierzycielami.
Temat: Próbkowanie w statystyce
1. Pojęcie obserwacji selektywnej, jej zadania
Obserwację statystyczną można zorganizować w sposób ciągły i nieciągły. Ciągła obserwacja obejmuje badanie wszystkich jednostek badanej populacji i wiąże się z dużymi kosztami pracy i materiałów. Można przeprowadzić badanie nie wszystkich jednostek populacji, ale tylko części, według której należy ocenić właściwości całej populacji jako całości nieciągły obserwacja. W praktyce statystycznej najczęściej spotyka się wybiórcza obserwacja.
Selektywna obserwacja - jest to rodzaj obserwacji nieciągłej, w której dobór jednostek do badania odbywa się w kolejności losowej, badana jest wybrana część, a wyniki rozkładane są na całą populację pierwotną. Obserwacja jest zorganizowana w ten sposób, że ta część wybranych jednostek ma zmniejszoną skalę reprezentuje(reprezentuje) całą populację.
Populacja, z której dokonuje się selekcji, nazywa się ogólny, ogólny.
Nazywa się zbiór wybranych jednostek zestaw do pobierania próbek, i wszystkie jego ogólne wskaźniki - selektywny.
Istnieje wiele powodów, dla których w wielu przypadkach preferuje się obserwację selektywną zamiast obserwacji ciągłej. Najważniejsze z nich to:
Oszczędność czasu i pieniędzy w wyniku zmniejszenia nakładu pracy;
Minimalizacja uszkodzeń lub zniszczeń badanych obiektów (określenie wytrzymałości przędzy na zerwanie, badanie żarówek elektrycznych na czas palenia, sprawdzenie dobrej jakości konserw);
Konieczność szczegółowego zbadania każdej jednostki obserwacji, gdy nie jest możliwe uwzględnienie wszystkich jednostek (przy badaniu budżetu rodzin);
Osiągnij większą dokładność wyników ankiet poprzez redukcję błędów rejestracji.
Przewaga obserwacji selektywnej nad obserwacją ciągłą może zostać zrealizowana, jeśli będzie ona zorganizowana i prowadzona w ścisłej zgodności z zasadami naukowymi. teoria metody pobierania próbek. Zasady te to: zapewnienie szansa(równe szanse znalezienia się w próbie) doboru jednostek oraz ich wystarczająca liczba. Przestrzeganie tych zasad pozwala uzyskać obiektywną gwarancję reprezentatywności uzyskanej próbki. pojęcie reprezentatywność Przez wybraną populację nie należy rozumieć jej reprezentacji w kategoriach wszystkich cech badanej populacji, a jedynie w odniesieniu do tych cech, które są badane lub mają istotny wpływ na kształtowanie podsumowujących cech uogólniających.
Głównym zadaniem obserwacji próby w ekonomii jest uzyskanie rzetelnych ocen na temat wskaźników średniej i udziału w populacji ogólnej na podstawie charakterystyki populacji próby (średnia i udział). Jednocześnie należy pamiętać, że w każdym badaniu statystycznym (solidnym i selektywnym) powstają błędy dwojakiego rodzaju: rejestracyjny i reprezentatywny.
Błędy rejestracyjne może mieć losowy(niezamierzone) i systematyczny(tendencyjny) charakter. Losowe błędy zazwyczaj równoważą się, gdyż nie mają dominującego kierunku w kierunku zawyżania lub niedoszacowania wartości badanego wskaźnika. Błędy systematyczne skierowane w jednym kierunku ze względu na celowe naruszenie zasad selekcji (stronnicze cele). Można ich uniknąć przy odpowiedniej organizacji i monitorowaniu.
Błędy reprezentatywności są nieodłącznie związane jedynie z obserwacją selektywną i wynikają z faktu, że próbka nie w pełni odtwarza próbkę ogólną. Reprezentują one rozbieżność pomiędzy wartościami wskaźników uzyskanych z próbki a wartościami wskaźników o tych samych wartościach, które uzyskano by przy obserwacji ciągłej prowadzonej z tym samym stopniem dokładności, tj. pomiędzy wartości wybranych i odpowiadających im wskaźników ogólnych.
Dla każdej konkretnej obserwacji próbki wartość błędu reprezentatywności można wyznaczyć za pomocą odpowiednich wzorów, od których zależy typ, metoda I sposób tworzenie próbki.
Według rodzaju Istnieje selekcja indywidualna, grupowa i łączona. Na indywidualny wybór do próby dobierane są poszczególne jednostki populacji ogólnej; Na wybór grupy- jakościowo jednorodne grupy lub serie badanych jednostek; łączony wybór obejmuje kombinację pierwszego i drugiego typu.
Według metody selekcji wyróżnić powtarzający się I niepowtarzające się pobieranie próbek.
Na ponowne próbkowanie całkowita liczba jednostek populacji objętych procesem pobierania próbek pozostaje niezmieniona. Ta czy inna jednostka, która znalazła się w próbie, po zarejestrowaniu, wraca ponownie do populacji ogólnej i zachowuje równe szanse ze wszystkimi innymi jednostkami, gdy jednostki zostaną ponownie wybrane do próby („dobór według schemat piłki zwróconej”). Ponowne próbkowanie w życiu społeczno-gospodarczym jest rzadkie. Zazwyczaj pobieranie próbek jest zorganizowane według schematu jednorazowego pobierania próbek.
Na bez ponownego próbkowania jednostka populacji, która znalazła się w próbie, nie jest zwracana do populacji ogólnej i nie uczestniczy w przyszłości w próbie; tj. kolejna próba jest pobierana z populacji ogólnej bez wybranych wcześniej jednostek („dobór według schematu kulki niezwróconej”). Zatem przy niepowtarzającym się próbkowaniu liczba jednostek w populacji ogólnej zmniejsza się w procesie badawczym.
Metoda selekcji definiuje specyficzny mechanizm lub procedurę wyboru jednostek z populacji.
W zależności od stopnia pokrycia jednostek populacji istnieją duży I mały (N <30) выборки.
W praktyce badań reprezentacyjnych najczęściej stosuje się następujące rodzaje próbkowania: właściwe losowe, mechaniczne, typowe, seryjne, kombinowane.
Główne cechy parametrów populacji ogólnej i próbnej są oznaczone symbolami:
N-objętość populacji ogólnej (liczba jednostek w niej zawartych);
P - wielkość próby (liczba badanych jednostek);
- średnia ogólna (średnia wartość atrybutu w populacji ogólnej);
Średnia próbka;
P- udział ogólny (udział jednostek posiadających daną wartość atrybutu w ogólnej liczbie jednostek populacji ogólnej);
w - udział próbki;
- wariancja ogólna (wariancja cechy w populacji ogólnej);
S 2 - wariancja próbki tej samej cechy;
- odchylenie standardowe w populacji ogólnej;
S- odchylenie standardowe w próbie.
2. Błędy próbkowania
Podczas obserwacji selektywnej należy o to zadbać szansa wybór jednostki. Każda jednostka musi mieć równe szanse, aby zostać wybrana wraz z innymi. Na tym opiera się dobór losowy.
DO właściwa próbka losowa odnosi się do wybierania jednostek z całej populacji ogólnej (bez wcześniejszego podziału jej na jakiekolwiek grupy) w drodze loterii (głównie) lub innej podobnej metody, na przykład z wykorzystaniem tabeli liczb losowych. Losowy wybór - wybór ten nie jest przypadkowy. Zasada losowości sugeruje, że na włączenie lub wykluczenie obiektu z próbki nie może mieć wpływu żaden inny czynnik niż przypadek. Przykład faktycznie losowe Losowania wygranych mogą służyć jako selekcja: z całkowitej liczby wystawionych losów losowo wybierana jest pewna część liczb stanowiących wygraną. Co więcej, wszystkie liczby mają równe szanse na dostanie się do próbki. W takim przypadku liczbę jednostek wybranych w próbie ustala się zwykle na podstawie przyjętej proporcji próby.
Udostępnij, próbki to stosunek liczby jednostek w populacji próbnej do liczby jednostek w populacji ogólnej:
![]()
Czyli przy 5% próbce z partii części po 1000 sztuk. wielkość próbki P wynosi 50 jednostek, a przy próbie 10% -100 jednostek. itp. Przy odpowiedniej naukowej organizacji pobierania próbek błędy reprezentatywności można zredukować do wartości minimalnych, dzięki czemu obserwacja selektywna staje się dość dokładna.
Dobór samolosowy „w czystej postaci” jest rzadko stosowany w praktyce obserwacji selektywnej, jest jednak początkowym spośród wszystkich innych rodzajów selekcji, zawiera i realizuje podstawowe zasady obserwacji selektywnej.
Rozważmy kilka zagadnień z teorii metody doboru próby i wzoru na błąd dla prostej próby losowej.
Stosując metodę próbkowania w statystyce, zwykle stosuje się dwa główne typy wskaźników uogólniających: średnia wartość cechy ilościowej I względna wartość alternatywnej cechy(proporcja lub proporcja jednostek w populacji statystycznej, która różni się od wszystkich innych jednostek tej populacji jedynie obecnością badanej cechy).
Przykładowy udział ( w ), lub częstotliwość, określa się na podstawie stosunku liczby jednostek posiadających badaną cechę T, do całkowitej liczby jednostek próby P:
w = t/n.
Przykładowo, jeśli na 100 przykładowych części (u = 100) 95 okazało się standardowych (T=95), następnie frakcja próbki
w = 95 / 100 = 0,95 .
Aby scharakteryzować wiarygodność przykładowych wskaźników, istnieją środek I marginalny błąd próbkowania.
Błąd próbkowania lub innymi słowy błąd reprezentatywności to różnica między odpowiednią próbą a ogólną charakterystyką:
![]() (1)
(1)
![]() (2)
(2)
Błąd próbkowania jest nieodłącznym elementem jedynie obserwacji próbek. Im większa wartość tego błędu, tym bardziej przykładowe wskaźniki różnią się od odpowiednich wskaźników ogólnych.
Średnia próbki i proporcja próbki są z natury rzeczy zmienne losowe, które mogą przyjmować różne wartości w zależności od tego, jakie jednostki populacji zostały uwzględnione w próbie. Dlatego błędy próbkowania są również zmiennymi losowymi i mogą przyjmować różne wartości. Dlatego określa się średnią możliwych błędów - średni błąd próbkowania.
Od czego to zależy oznacza błąd próbkowania! Z zastrzeżeniem zasady doboru losowego, średni błąd próbkowania określa się przede wszystkim: wielkość próbki: im większa populacja, ceteris paribus, tym mniejszy średni błąd próbkowania. Obejmując badanie reprezentacyjne coraz większą liczbą jednostek populacji ogólnej, coraz dokładniej charakteryzujemy całą populację.
Średni błąd próbkowania zależy również od stopień zmienności badana cecha. Jak wiadomo, stopień zmienności charakteryzuje się dyspersją Lub w (1 - w ) - dla funkcji alternatywnej. Im mniejsza zmienność cechy, a co za tym idzie wariancja, tym mniejszy średni błąd próbkowania i odwrotnie. Przy zerowym rozproszeniu (atrybut się nie zmienia) średni błąd próbkowania wynosi zero, tj. każda jednostka populacji ogólnej będzie dokładnie charakteryzowała całą populację zgodnie z tym atrybutem.
Zależność średniego błędu próbkowania od jego wielkości i stopnia zmienności cechy znajduje odzwierciedlenie we wzorach, które można zastosować do obliczenia średniego błędu próbkowania w warunkach obserwacji próbki, gdy ogólna charakterystyka ( x, p) są nieznane i dlatego nie jest możliwe wyznaczenie rzeczywistego błędu próbkowania bezpośrednio ze wzorów (1), (2).
Z losowym wyborem błędy średnie teoretycznie oblicza się za pomocą następujących wzorów:
dla średniej cechy ilościowej
![]() (3)
(3)
dla lemiesza (charakterystyka alternatywna)
![]() (4)
(4)
Ponieważ w praktyce jest to wariancja cechy w populacji ogólnej nie do końca znane, w praktyce się je stosuje
wartość dyspersji S 2 , obliczana dla populacji próby na podstawie prawa wielkich liczb, zgodnie z którym populacja próby o odpowiednio dużej liczebności dokładnie odtwarza cechy populacji ogólnej.
Zatem formuły obliczeniowe średni błąd próbkowania losowe ponowne próbkowanie będzie wyglądało następująco:
dla średniej cechy ilościowej
dla lemiesza (charakterystyka alternatywna)
![]() (6)
(6)
Wariancja populacji próbnej nie jest jednak równa wariancji populacji ogólnej, dlatego też średnie błędy próby obliczone za pomocą wzorów (5) i (6) będą miały charakter przybliżony. Jednak w teorii prawdopodobieństwa udowodniono, że wariancja ogólna wyraża się poprzez wariancję próbki w następujący sposób:
![]() (7)
(7)
Ponieważ P / (N-1) dla wystarczająco dużych P - wartość bliską jedności, można przyjąć, że = S 2 , A dlatego też wzory (5) i (6) można stosować w praktycznych obliczeniach średnich błędów próbkowania. I tylko w przypadku małej próby (kiedy liczebność próby nie przekracza 30) konieczne jest uwzględnienie współczynnika n/(n-1) i oblicz mała próbka oznacza błąd według wzoru:
 (8)
(8)
w powyższych wzorach do obliczania średnich błędów próbkowania należy pomnożyć wyrażenie radykalne przez 1-(p/ N ), ponieważ w procesie jednorazowego pobierania próbek zmniejsza się liczba jednostek w populacji ogólnej. Dlatego w przypadku niepowtarzającego się pobierania próbek stosuje się wzory obliczeniowe średni błąd próbkowania przyjmie następującą postać:
dla średniej cechy ilościowej
 (9)
(9)
dla lemiesza (charakterystyka alternatywna)
![]() (10)
(10)
Ponieważ P zawsze mniej N , następnie dodatkowy współczynnik 1 - (n / N ) zawsze będzie mniejsza niż jeden. Wynika z tego, że średni błąd przy selekcji jednorazowej będzie zawsze mniejszy niż przy selekcji powtarzanej. Jednocześnie przy stosunkowo niewielkim odsetku próby współczynnik ten jest bliski jedności (np. przy próbie 5% wynosi 0,95, przy próbie 2% wynosi 0,98 itd.). Dlatego w praktyce czasami do określenia średniego błędu próbkowania bez określonego mnożnika stosuje się wzory (5) i (6), mimo że próba zorganizowana jest jako niepowtarzalna. Dzieje się tak, gdy liczba jednostek w populacji N nieznane lub nieograniczone, lub kiedy P bardzo mało w porównaniu do N, i w zasadzie wprowadzenie dodatkowego współczynnika bliskiego jedności praktycznie nie wpłynie na wartość średniego błędu próbkowania.
Próbkowanie mechaniczne polega na tym, że dobór jednostek w zbiorze próby z ogółu, podzielonych neutralnym kryterium na równe przedziały (grupy), odbywa się w taki sposób, że z każdej takiej grupy w próbie wybierana jest tylko jedna jednostka. Aby uniknąć stronniczości, należy wybrać jednostkę znajdującą się pośrodku każdej grupy.
Organizując selekcję mechaniczną, jednostki populacji są wstępnie ułożone (zwykle na liście) w określonej kolejności (na przykład alfabetycznie, według lokalizacji, w kolejności rosnącej lub malejącej wartości jakiegoś wskaźnika, który nie jest związane z badaną nieruchomością itp.), po czym mechanicznie, po określonym czasie, wybiera się określoną liczbę jednostek. W tym przypadku wielkość przedziału w populacji ogólnej jest równa odwrotności udziału w próbie. Zatem przy próbce 2% wybiera się i sprawdza co 50. jednostkę (1:0,02), przy próbie 5% - co 20. jednostkę (1:0,05), np. część schodzącą z maszyny.
Przy dostatecznie dużej populacji dobór mechaniczny pod względem dokładności wyników jest zbliżony do losowego właściwego. Dlatego do wyznaczenia błędu średniego próbkowania mechanicznego stosuje się wzory na samolosowe i niepowtarzające się pobieranie próbek (9), (10).
Aby wybrać jednostki z heterogenicznej populacji, należy zastosować tzw typowa próbka, który jest stosowany w przypadkach, gdy wszystkie jednostki populacji ogólnej można podzielić na kilka jakościowo jednorodnych, podobnych grup według cech wpływających na badane wskaźniki.
Przy badaniu przedsiębiorstw takimi grupami mogą być np. branże i podsektory, formy własności. Następnie z każdej typowej grupy dokonuje się indywidualnego doboru jednostek do próby poprzez odpowiednią próbkę losową lub mechaniczną.
Typowe próbkowanie jest zwykle stosowane w badaniu złożonych populacji statystycznych. Na przykład w reprezentacyjnym badaniu budżetów rodzinnych pracowników i pracowników w niektórych sektorach gospodarki, wydajność pracy pracowników w przedsiębiorstwie jest reprezentowana przez oddzielne grupy umiejętności.
Typowe próbkowanie daje dokładniejsze wyniki niż inne metody doboru jednostek w populacji próbnej. Typizacja populacji ogólnej zapewnia reprezentatywność takiej próby, reprezentację w niej każdej grupy typologicznej, co pozwala wykluczyć wpływ rozproszenia międzygrupowego na średni błąd próby,
Przy ustalaniu średni błąd typowej próbki służy jako wskaźnik zmienności. średnia wariancji wewnątrzgrupowych.
Średni błąd próbkowania można znaleźć za pomocą wzorów:
dla średniej cechy ilościowej
(ponowny wybór); (11)
 (wybór jednorazowy); (
12)
(wybór jednorazowy); (
12)
dla lemiesza (charakterystyka alternatywna)
![]() (ponowny wybór); (13)
(ponowny wybór); (13)
 (wybór jednorazowy), (14)
(wybór jednorazowy), (14)
Gdzie - średnia rozproszeń wewnątrzgrupowych dla populacji próby;
Średnia wariancji wewnątrzgrupowych udziału (alternatywa
cecha) w populacji próbnej.
próbkowanie seryjne polega na losowym doborze z ogólnej populacji nie pojedynczych jednostek, ale ich równych grup (gniazd, szeregów) w celu poddania obserwacji wszystkich jednostek bez wyjątku w takich grupach.
Stosowanie pobierania próbek seryjnych wynika z faktu, że wiele towarów w celu ich transportu, przechowywania i sprzedaży pakowanych jest w opakowania, pudełka itp. Dlatego też podczas kontroli jakości pakowanego towaru bardziej racjonalne jest sprawdzenie kilku opakowań (serii) niż wybieranie wymaganej ilości towaru ze wszystkich opakowań.
Ponieważ wszystkie jednostki bez wyjątku są badane w obrębie grup (serii), średni błąd próbkowania (przy wyborze równych serii) zależy wyłącznie od wariancji międzygrupowej (międzyserialnej).
Średni błąd próbkowania dla średniego wyniku podczas selekcji seryjnej można je znaleźć za pomocą wzorów:
(ponowny wybór); ( 15 )
![]() (wybór jednorazowy), ( 16
)
(wybór jednorazowy), ( 16
)
Gdzie R- liczba wybranych serii; R - łączna liczba odcinków.
Wariancję międzygrupową próbki seryjnej oblicza się w następujący sposób: ![]()
gdzie jest średnia i-tego szeregu; - ogólna średnia dla całej próbki.
Średni błąd próbkowania dla proporcji (cecha alternatywna) w wyborze serialu:
![]() (ponowny wybór); ( 17
)
(ponowny wybór); ( 17
)
 (wybór jednorazowy). ( 18
)
(wybór jednorazowy). ( 18
)
Międzygrupa(między seriami) wariancja proporcji próbki seryjnej określone wzorem:
![]() (19)
(19)
Gdzie w I - proporcja cechy w szeregu i; - całkowity udział cechy w całej próbie.
W praktyce badań statystycznych, oprócz rozważanych wcześniej metod selekcji, stosuje się ich kombinację. (wybór łączony).
3. Rozszerzenie wyników próby na populację
Ostatecznym celem obserwacji próby jest scharakteryzowanie populacji ogólnej na podstawie wyników próby.
Przykładowe średnie i wartości względne rozdziela się na populację ogólną, biorąc pod uwagę granicę ich możliwego błędu.
W każdej konkretnej próbie rozbieżność między średnią z próby a ogólną, tj. może być mniejszy niż średni błąd próbkowania , równa lub większa od niej.
Co więcej, każda z tych rozbieżności ma inny charakter prawdopodobieństwo(obiektywna możliwość zaistnienia zdarzenia). Dlatego rzeczywiste rozbieżności między średnią z próby a ogólną można uznać za pewien błąd krańcowy powiązany z błędem średnim i gwarantowany z pewnym prawdopodobieństwem R.
Krańcowy błąd próbkowania dla średniej () Na ponowny wybór można obliczyć korzystając ze wzoru:
 (20)
(20)
Gdzie T- odchylenie znormalizowane - „współczynnik ufności”, zależny od prawdopodobieństwa, z jakim gwarantowany jest marginalny błąd próbkowania;
Średni błąd próbkowania.
Formułę można zapisać w podobny sposób marginalny błąd próbkowania dla ułamka po ponownym wybraniu:
![]() (21)
(21)
Z losowym, niepowtarzalnym wyborem we wzorach obliczania krańcowych błędów próbkowania (20) i (21) należy pomnożyć wyrażenie radykalne przez 1 - ( N / N ) .
Wzór na krańcowy błąd próbkowania wynika z podstawowych założeń teorii metody doboru próby, sformułowanych w szeregu twierdzeń teorii prawdopodobieństwa, odzwierciedlających prawo wielkich liczb.
Na podstawie P.L. Czebyszewa (z wyjaśnieniami A.M. Lapunowa) z prawdopodobieństwem arbitralnie bliskim jedności można argumentować, że przy wystarczająco dużej liczebności próby i ograniczonej wariancji ogólnej wskaźniki uogólniające próbę (średnia, udział) będą arbitralnie niewiele różnić się od odpowiednich wskaźników ogólnych.
Jeśli chodzi o znalezienie środek wartości cech, twierdzenie to można zapisać w następujący sposób:
![]() (22)
(22)
i dla Akcje podpisać:
![]() (23
)
(23
)
Gdzie  (24)
(24)
Zatem wartość krańcowego błędu próbkowania można wyznaczyć z pewnym prawdopodobieństwem.
Wartości funkcji F( T ) przy różnych wartościach T jako współczynnik krotności średniego błędu próbkowania, wyznaczane są na podstawie specjalnie opracowanych tabel. Oto kilka wartości, które są najczęściej używane w przypadku próbek o wystarczająco dużym rozmiarze ( N 30):
T 1,000 1,960 2,000 2,580 3,000
F( T ) 0,683 0,950 0,954 0,990 0,997
Krańcowy błąd próbkowania odpowiada na pytanie o dokładność próbkowania z pewnym prawdopodobieństwem, którego wartość wyznacza współczynnik T(w obliczeniach praktycznych z reguły podane prawdopodobieństwo nie powinno być mniejsze niż 0,95). Tak, o godz T= będzie 1 błąd marginalny = . Można zatem z prawdopodobieństwem 0,683 stwierdzić, że różnica między próbą a wskaźnikami ogólnymi nie przekroczy jednego średniego błędu próby. Inaczej mówiąc, w 68,3% przypadków błąd reprezentatywności nie będzie przekraczał ±1.
Na T = 2 z prawdopodobieństwem 0,954 nie przekroczy ±2,
Na T = 3 z prawdopodobieństwem 0,997 - powyżej ±3 itd.
Jak widać z powyższych wartości funkcji F (T) (patrz ostatnia wartość), prawdopodobieństwo błędu równego lub większego niż trzykrotność średniego błędu próbki, tj. 3 jest niezwykle małe i wynosi 0,003, czyli 1-0,997. Takie mało prawdopodobne zdarzenia są uważane za praktycznie niemożliwe i dlatego mają wartość = 3 można przyjąć jako granicę możliwego błędu próbkowania.
Obserwację próby przeprowadza się w celu rozszerzenia wniosków uzyskanych z danych próby na populację ogólną. Jednym z głównych zadań jest ocena badanych cech (parametrów) populacji ogólnej na podstawie danych próbnych.
Krańcowy błąd próbkowania pozwala określić wartości graniczne cech populacji ogólnej i ich przedziały ufności:
dla środka (25)
do udostępnienia (26)
Oznacza to, że przy danym prawdopodobieństwie można stwierdzić, że wartości średniej ogólnej należy oczekiwać w przedziale od - zanim +
Podobnie można zapisać przedział ufności ułamka ogólnego: ![]()
Wraz z wartością bezwzględną marginalnego błędu próbkowania, marginalny względny błąd próbkowania, który definiuje się jako procent krańcowego błędu próbkowania w stosunku do odpowiedniej cechy próbki:
dla średniej,%: ![]() (27)
(27)
do udostępnienia, %: (28)
Rozważmy znalezienie średnich i krańcowych błędów próbkowania, określenie granic ufności średniej i proporcji na konkretnych przykładach.
Zadanie 1. Aby określić szybkość rozliczeń z wierzycielami przedsiębiorstw korporacyjnych w banku komercyjnym, przeprowadzono losową próbę 100 dokumentów płatniczych, dla których średni czas przekazania i otrzymania pieniędzy wyniósł 22 dni ( = 22) z odchyleniem standardowym wynoszącym 6 dni (S= 6).
Wymagane z prawdopodobieństwem P. = 0,954 w celu ustalenia błędu krańcowego średniej próby i granic ufności średniego czasu trwania rozliczeń przedsiębiorstw tej korporacji.
Rozwiązanie. błąd marginalny = T określa formuła reselekcji (6.20), ponieważ wielkość populacji ogólnej N nieznany. Z prezentowanych wartości F (T) (patrz str. 98) dla prawdopodobieństwa R= 0,954 znaleziska T = 2.
Zatem marginalny błąd próbkowania, dni:
![]()
![]()
Ogólna średnia będzie = ± , a przedziały ufności (granice) średniej ogólnej oblicza się na podstawie podwójnej nierówności:
![]()
![]()
Zatem z prawdopodobieństwem 0,954 można stwierdzić, że średni czas trwania rozliczeń przedsiębiorstw tej korporacji waha się od 20,8 do 23,2 dni.
Zadanie 2. Spośród 1000 rodzin wybranych w województwie pod względem dochodu na osobę (próba 2%, mechaniczne) 300 rodzin okazało się osiągać niskie dochody.
Wymagane jest określenie z prawdopodobieństwem 0,997 odsetka rodzin o niskich dochodach w całym województwie.
Rozwiązanie. Udział próby (udział rodzin o niskich dochodach wśród badanych rodzin) jest równy:
Według wcześniej zaprezentowanych danych F( T) dla prawdopodobieństwa 0,997 znajdujemy T= 3 (patrz s. 99). Błąd krańcowy udziału wyznacza się ze wzoru na dobór jednorazowy (pobieranie mechaniczne jest zawsze jednorazowe):
Limit względnego błędu próbkowania,%:
Udział ogólny i granice ufności udziału ogólnego oblicza się na podstawie podwójnej nierówności:
W naszym przykładzie:
Można więc niemal wiarygodnie, z prawdopodobieństwem 0,997, stwierdzić, że odsetek rodzin o niskich dochodach wśród wszystkich rodzin w województwie waha się od 28,6 do 31,4%.
Zadanie 3. W celu określenia plonu zbóż przeprowadzono badanie reprezentacyjne 100 gospodarstw rolnych regionu o różnych formach własności, w wyniku którego uzyskano dane zbiorcze (tab. 6.1). Należy z prawdopodobieństwem 0,954 wyznaczyć błąd krańcowy średniej próby oraz granice ufności średniego plonu zbóż dla wszystkich gospodarstw w regionie.
Tabela 6.1
Rozkład plonów w gospodarstwach regionu o różnych formach własności
Rozwiązanie. Ponieważ badane gospodarstwa regionu pogrupowane są według własności, błąd krańcowy przeciętnego plonu wyznacza się ze wzoru dla próby typowej, przeprowadzonego metodą doboru powtórnego (liczba populacji ogólnej N nie jest znana):
We wzorze tym średnia wariancji wewnątrzgrupowych jest nieznana.
Oblicza się go według wzoru:
Według danych przedstawionych wcześniej (por. s. 98) F (T) dla prawdopodobieństwa R=0,954 znalezienia T = 2.
Następnie marginalny błąd próbkowania, c/ha:

Średnia ogólna: = ± . Aby znaleźć jego granice, należy najpierw obliczyć średni plon dla populacji próbnej , c/ha:
Limit względnego błędu próbkowania,%:
![]()
Granice ufności średniej ogólnej oblicza się na podstawie podwójnej nierówności:
![]()
Zatem z prawdopodobieństwem 0,954 można zagwarantować, że średni plon zbóż w regionie będzie nie mniejszy niż 20 centów z hektara, ale nie większy niż 22 centy z hektara.
Określenie wymaganej wielkości próbki. Projektując obserwację próbną o zadanej wartości dopuszczalnego błędu próbkowania, bardzo ważne jest prawidłowe określenie liczebności (objętości) populacji próby, która z określonym prawdopodobieństwem zapewni zadaną dokładność wyników obserwacji. Wzory określania wymaganej wielkości próbki Płatwo uzyskać bezpośrednio z przykładowych wzorów na błędy.
Zatem ze wzorów na marginalny błąd próbkowania dla ponowny wybórłatwo to (po podniesieniu obu stron równości do kwadratu) wyrazić wymagana wielkość próbki:
dla średniej cechy ilościowej
dla lemiesza (charakterystyka alternatywna)
![]() (30
)
(30
)
Podobnie ze wzorów na marginalny błąd próbkowania dla wybór nie powtarzalny znaleźliśmy to
 (dla średniej);
(31
)
(dla średniej);
(31
)
 (do udostępnienia).
(32
)
(do udostępnienia).
(32
)
Wzory te pokazują, że wraz ze wzrostem szacowanego błędu próbkowania wymagana wielkość próby znacznie maleje.
Aby obliczyć wielkość próby, musisz znać wariancję. Można je zapożyczyć z wcześniejszych badań tej samej lub podobnej populacji, a jeśli nie są one dostępne, należy przeprowadzić specjalne badanie reprezentacyjne o małej liczebności w celu określenia wariancji.
Zadanie 4. Aby określić średni wiek 1200 studentów wydziału, konieczne jest przeprowadzenie badania losowego metodą losowego doboru jednorazowego. Wstępnie ustalono, że odchylenie standardowe wieku uczniów wynosi 10 lat.
Ilu uczniów należy przebadać, aby z prawdopodobieństwem 0,954 średni błąd losowania nie przekroczył 3 lat?
Rozwiązanie. Obliczmy wymaganą liczebność próby, osoby, zgodnie ze wzorem doboru jednorazowego (6.31), przyjmując, że t = 2 przy R = 0,954:
Zatem próba 47 osób. zapewnia określoną dokładność przy jednorazowym wyborze.
Metoda doboru próby jest szeroko stosowana w praktyce statystycznej w celu uzyskania informacji gospodarczych.
Metoda selektywna nabiera ogromnego znaczenia w obecnych warunkach przejścia do gospodarki rynkowej. Zmiany charakteru powiązań gospodarczych, czynszów, własności poszczególnych zespołów i osób powodują zmiany w funkcjach rachunkowych i statystycznych, ograniczenie i uproszczenie sprawozdawczości. Jednocześnie rosnące wymagania wobec zarządzania zwiększają potrzebę dostarczania rzetelnej informacji i dalszego zwiększania jej efektywności. Wszystko to prowadzi do szerszego zastosowania metody doboru próby w gospodarce.
Pewne doświadczenia z badań reprezentacyjnych zostały już zgromadzone w statystyce krajowej.